|
|
|
发布时间: 2022-08-16 |
图像理解和计算机视觉 |
|
|
|


|
收稿日期: 2021-03-01; 修回日期: 2021-04-22; 预印本日期: 2021-04-29
基金项目: 国家自然科学基金项目(61971208, 61671225, 52061020, 61702128);云南省应用基础研究计划重点项目(2018FA034);云南省中青年学术技术带头人后备人才项目(Shen Tao, 2018);云南省万人计划青年拔尖人才项目(201873);昆明理工大学人才培养项目(KKSY201703016)
作者简介:
曾文健,1994年生, 男, 硕士研究生, 主要研究方向为计算机视觉和深度学习。E-mail:zengwenjian26@163.com
朱艳,通信作者,女,教授,硕士生导师,主要研究方向为智能检测和人工智能。E-mail:zhuyan@kust.edu.cn 沈韬,男,教授,主要研究方向为太赫兹材料无损检测、辅助驾驶和人工智能。E-mail:shentao@kmust.edu.cn 曾凯,男,副教授,主要研究方向为粒计算和分布式计算。E-mail:zengkailink@sina.com 刘英莉,女,讲师,主要研究方向为材料文本挖掘和深度学习。E-mail:lyl2002@126.com *通信作者: 朱艳 zhuyan@kust.edu.cn
中图法分类号: TP391
文献标识码: A
文章编号: 1006-8961(2022)08-2496-10
|
摘要
目的 太赫兹由于穿透性强、对人体无害等特性在安检领域中得到了广泛关注。太赫兹图像中目标尺寸较小、特征有限,且图像分辨率低,目标边缘信息模糊,目标信息容易和背景信息混淆,为太赫兹图像检测带来了一定困难。方法 本文在YOLO(you only look once)算法的基础上提出了一种融合非对称特征注意力和特征融合的目标检测网络AFA-YOLO(asymmetric feature attention-YOLO)。在特征提取网络CSPDarkNet53(cross stage paritial DarkNet53)中设计了非对称特征注意力模块。该模块在浅层网络中采用非对称卷积强化了网络的特征提取能力,帮助网络模型在目标特征有限的太赫兹图像中提取到更有效的目标信息;使用通道注意力和空间注意力机制使网络更加关注图像中目标的重要信息,抑制与目标无关的背景信息;AFA-YOLO通过增加网络中低层到高层的信息传输路径对高层特征进行特征融合,充分利用到低层高分辨率特征进行小目标的检测。结果 本文在太赫兹数据集上进行了相关实验,相比原YOLOv4算法,AFA-YOLO对phone的检测精度为81.15%,提升了4.12%,knife的检测精度为83.06%,提升了3.72%。模型平均精度均值(mean average precision, mAP)为82.36%,提升了3.92%,漏警率(missing alarm, MA)为12.78%,降低了2.65%,帧率为32.26帧/s,降低了4.06帧/s。同时,本文在太赫兹数据集上对比了不同的检测算法,综合检测速度、检测精度和漏警率,AFA-YOLO优于其他目标检测算法。结论 本文提出的AFA-YOLO算法在保证实时性检测的同时有效提升了太赫兹图像中目标的检测精度并降低了漏警率。
关键词
太赫兹图像; 小尺度目标检测; YOLOv4; 非对称卷积; 注意力机制; 特征融合
Abstract
Objective Terahertz technology has great application potentials in related to wireless communications, biomedicine, and non-destructive testing. Some terahertz imaging features are suitable for hidden objects detection for human security inspections because terahertz waves can penetrate the substance like ceramics, plastics and cloths and are largely absorbed or reflected by metals, liquids and other substances with no harmless on human body. With the development of terahertz imaging technology and the increasing flow of people in application scenarios, the use of artificial recognition of terahertz images is no longer applicable. In order to solve the problem of hidden objects and dangerous goods detection, current research have focused on using deep learning method to classify and analyze them. Due to the resolution and contrast of the terahertz image are low, the edge information of the target in the image is blurred, the target information is easily confused with the background information, and the target information is unclear in the terahertz image, and the feature information is limited. Therefore, the effectiveness issue of feature information to detect the target in terahertz image is challenged for terahertz image detection. Method We facilitates a target detection framework asymmetric feature attention-you only look once(AFA-YOLO) that combines asymmetric feature attention and feature fusion based on the you only look once v4(YOLOv4) algorithm to resolve the barriers of small-scale target detection in terahertz images.cross stage paritial DarkNet53(CSPDarkNet53) is as a feature extraction network for AFA-YOLO and an asymmetric feature attention module in CSPDarkNet53 is designed. First, this module uses asymmetric convolution in the shallow network to enhance the feature extraction capabilities of the network, helping the network model to extract more effective target information from the terahertz image with limited target features; Second, the module melts convolutional block attention module(CBAM) attention force mechanism via using the channel attention mechanism to make the model pay more attention to the important information of the target in the image, suppress unrelated background information to the target, and use the spatial attention mechanism to pay attention to the position information of the target in the terahertz image, allowing the model to optimize target contexts. AFA-YOLO has carried out feature fusion operations as well, the high-level features are enhanced through increasing the information transmission path from the low-level to the high-level in the network. The high-level feature map can obtain fine-grained target appearance information and the positioning and detection of small-scale targets in terahertz images can be optimized. Result Our research uses the detection accuracy map, missed alarm (MA) rate and detection speed frames per second(FPS) as indicators to carry out related experiments on the terahertz data set. The detection accuracy of AFA-YOLO for the phone is 81.15% compare to the original YOLOv4 algorithm, which is an increase of 4.12%. The detection accuracy of knife is 83.06%, an increased ratio of 3.72%. The model mean average precision(mAP) is 82.36%, which is an increased ratio of 3.92%. The MA is 12.78%, which is a decreased ratio of 2.65%, and the FPS is 32.26, which is lower to 4.06. Additionally, we conduct comparative analysis of different detection algorithms on the terahertz dataset. AFA-YOLO optimized target detection algorithms in terms of recognized detection speed, detection accuracy and missed alarm rate. Conclusion We facilitate an AFA-YOLO detection framework that combines asymmetric feature attention and feature fusion. Our YOLOv4-based framework melts asymmetric feature attention module into the shallow network and enhances the target information on the high-level feature map. The optimal information ensures real-time detection through improving the detection accuracy of the target in the terahertz image effectively and lowering the missed alarm rate.
Key words
terahertz image; small target detection; YOLOv4; asymmetric convolution; attention mechanism; featurefusion
0 引言
太赫兹(Mittleman,2017)泛指频率在0.1~10 THz波段内的电磁波,是21世纪最具潜力的新兴技术之一,在无线通信、生物医学和无损检测都有着巨大的应用前景。由于太赫兹波对人体无害,并且可以穿透陶瓷、塑料和布料等,同时被金属、液体等物质大量吸收或反射,这些特性使得太赫兹成像非常适用于人体安检(Feng等,2020)中的隐匿物品检测。
近年来,基于卷积神经网络(convolutional neural network,CNN)的目标检测算法以其优异的检测性能和快速处理数据的能力在目标检测领域得到了广泛应用。现阶段的目标检测算法按检测流程分为两类;一类是以Faster R-CNN(region-convolutional neural network)(Ren等,2017)、Mask R-CNN(He等,2017)为代表的具有区域建议的两阶段目标检测算法,这些检测算法在检测精度上较高但是检测速度慢。另一类是以SSD(single shot multibox detector)(Liu等,2016)、YOLOv4(you only look once)(Bochkovskiy等,2020)等为代表的单阶段目标检测算法,这些检测算法能实现实时性的快速检测,但是在检测精度上低于两阶段的目标检测算法。
基于深度学习的目标检测算法虽然在对自然光学图像的检测中取得了较好的检测效果,但由于太赫兹图像的对比度较低,图像中目标的边缘信息模糊,导致背景信息容易与目标信息混淆;同时,由于太赫兹图像中的目标尺寸较小,目标特征有限,最后导致基于深度学习的目标检测方法对太赫兹图像的检测效果较差。因此,如何利用有限的特征信息来准确检测太赫兹图像中的目标是太赫兹图像检测的难点。
为了解决上述问题,本文在YOLOv4的基础上提出一种融合非对称特征注意力和特征融合的目标检测网络AFA-YOLO(asymmetric feature attention-YOLO)。AFA-YOLO在检测模型中加入非对称卷积(Ding等,2019)来增强模型对目标的特征提取能力,并且使用CBAM(convolutional block attention module)(Woo等,2018)注意力机制模块使模型关注图像中的有用特征,抑制冗余特征,从而减少背景信息对目标产生的干扰,降低漏检情况。本文的主要贡献如下:
1) 以YOLOv4检测网络为基础,针对太赫兹图像检测提出了一种融合非对称特征注意力和特征融合的目标检测网络AFA-YOLO,能有效提高对太赫兹图像中目标的检测精度并降低漏警率。
2) 设计了一种非对称特征注意力模块,该模块通过非对称卷积增强了网络对目标的特征提取能力,利用通道注意力关注到图像中目标的重要通道信息,利用空间注意力使网络关注图像中的关键区域。
3) 通过增加网络中的信息传输路径对高层特征进行特征增强,将低层高分辨率特征和具有丰富语义信息的高层特征融合,充分利用低层特征检测太赫兹图像中的小尺度目标。
4) 对比了不同的目标检测算法在太赫兹数据集上的检测效果。在满足实时性检测的前提下,AFA-YOLO在对太赫兹图像中小目标的检测上获得了最高的检测精度以及最低的漏警率,检测精度为82.36%,漏警率为12.78%。
1 相关工作
1.1 相关检测算法
Faster R-CNN是以VGG(Visual Geometry Group)网络为基础的两阶段目标检测算法,该算法将候选区域生成、特征提取、分类和位置精修统一到一个网络结构中,真正实现了端到端的目标检测,提高了检测速度和检测精度。但是在获取区域建议的过程中,由于计算量较大,无法达到实时性检测。Mask R-CNN对Faster R-CNN进行了扩展,添加了一个分支,使用现有的检测对目标进行并行的预测,并且在类别预测时做到了像素级别。
YOLO(Redmon等,2016)是常见的单阶段检测算法之一,YOLO将目标检测任务转化成一个回归问题,大大加快了检测速度。与Faster R-CNN不同的是,YOLO算法在训练和预测过程中利用全图信息,因此可以将背景预测错误率降低一半。但YOLO算法对小尺度目标的检测效果不太好,随后YOLO9000(Redmon和Farhadi,2017)、YOLOv3(Redmon和Farhadi,2018)等算法针对这一问题在不同程度上有了相关改进。本文中用到的YOLOv4算法平衡了检测精度和速度,可以在一块普通的GPU上完成训练,最后达到实时性检测。YOLOv4先通过由53个卷积层组成的网络CSPDarkNet53(cross stage paritial DarkNet53)进行特征提取,再由空间金字塔池化(spatial pyramid pooling, SPP)进行多尺度特征融合,同时路径聚合网络(path aggregation network, PANet)(Wang等,2019)会对提取到的特征进行特征增强,最后将特征图送入检测层进行目标检测操作。
SSD是常见的单阶段检测算法之一。主网络结构是VGG16,并将最后两个全连接层改成了卷积层。SSD算法与YOLO的不同之处是除了在最终特征图上做目标检测外,还在之前选取的5个特征图上进行预测,虽然提高了对小尺度目标的检测精度,但是SSD算法的缺点也很明显,需要人工设置先验框的尺寸大小和比例,并且对目标的召回率较低。
上述检测方法都实现了端到端的目标检测,将深度学习中的检测方法引入太赫兹图像的检测中可以大大减少人力资源的使用, 同时提高安检场景中的检测效率。但上述方法并不针对太赫兹图像中的目标检测,在对太赫兹图像的检测中检测精度较低, 同时存在较高的漏检。
1.2 太赫兹图像目标检测
在对太赫兹图像的检测研究中,目前研究人员通过改进相关的检测算法来提高对太赫兹图像的检测效果。Xiao等人(2018)提出了一种结合预处理和结构优化的框架R-PCNN(region-preprocessing convolutional neural networks),在Faster R-CNN网络中加入图像去噪和增强模块来解决传统的图像分割和定位方法对太赫兹图像检测精度和速度不够的问题。Zhang等人(2018)分析了太赫兹图像与光学图像的相似性,提出了基于光学特征迁移的分类方法和一种阈值分割结合Faster R-CNN的检测方法,用于独立检测人体和其他物体以提高检测性能;Yang等人(2019)通过稀疏低秩分解方法挖掘太赫兹图像的时空信息,实现对可疑对象的高精度自动检测和识别。
1.3 小尺度目标检测
在目标检测中,由于小尺度目标在图像中的信息较少导致检测小尺度目标要比检测中型和大型目标更困难。在COCO(common objects in context)评价标准中,图像中小于或者等于32×32像素的物体通常归类为小尺度目标。当前研究人员针对小尺寸目标检测也展开了相关的研究。Sommer等人(2017)用5个卷积层和3个全连接层组成的浅层神经网络来实现对航空图像中的小尺度目标检测。Gao等人(2018)先对图像进行下采样,然后使用强化学习动态地搜索感兴趣区域,最后以更高的分辨率对该区域进行小尺度目标检测。陈冰曲和邓涛(2019)针对车辆数据集重新设计了SSD算法的区域候选框, 并在SSD算法的损失函数基础上增加排斥损失提高对重叠目标检测。Liu等人(2020)提出一种基于反卷积区域的卷积神经网络来实现准确检测交通标志的问题。郭璠等人(2021)提出了一种基于语义分割的通道注意方法和空间注意方法YOLOv3-A来增强模型对交通标志的检测性能。
2 本文方法
2.1 AFA-YOLO检测网络
AFA-YOLO检测网络在CSPDarkNet53的浅层部分设计了一种非对称特征注意力模块,该模块结合了非对称卷积和CBAM注意力机制的优点来强化网络模型对太赫兹图像中目标的特征提取能力。图 1为AFA-YOLO的网络结构图,输入图像先经过非对称特征注意力模块和特征提取网络CSPDarkNet53进行特征提取,再由SPP流向路径聚合网络。由于小尺度目标依赖浅层网络提取的低层特征信息,因此,AFA-YOLO检测框架中进行了特征融合,将经过非对称特征注意力模块后的低层高分辨率特征和高层具有丰富语义信息的特征融合,充分利用低层特征图中目标的外观信息进行定位,如图 1中虚线所示,最后网络结合不同分辨率的YOLO检测层进行目标检测。
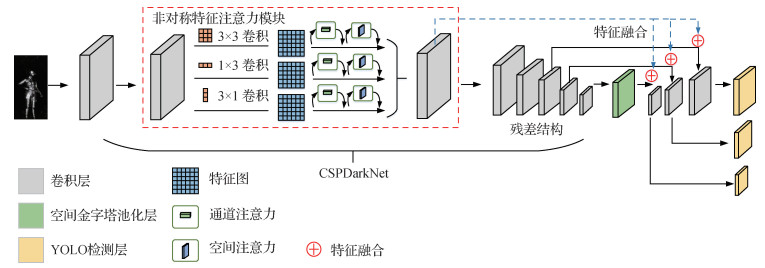

2.2 非对称特征注意力模块
2.2.1 非对称卷积
在太赫兹图像中,由于图像中目标尺寸相对较小,特征信息有限且图像中目标的边缘信息模糊,普通的方形卷积核对于太赫兹图像中目标的特征提取能力不足,不能突出卷积核提取到的目标特征。非对称卷积相比于普通方形的卷积增加了水平卷积和竖直卷积,新增的两个卷积核增强了方形卷积核中心骨架的特征提取能力,从而强化了方形卷积核中心的特征,弱化了边缘的特征,因此,非对称卷积能很好地帮助网络提取到目标的特征。图 2为非对称卷积。
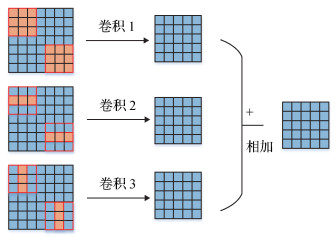
在AFA-YOLO的网络中,本文在特征提取网络CSPDarkNet53第1个卷积层之前使用非对称卷积将现有的3×3卷积核替换成3×3、1×3、3×1这3个并行的卷积核,这3个卷积核会分别对同一个输入特征进行特征提取操作,然后将这3个卷积核提取到的特征进行融合后得到该卷积层的输出结果。
2.2.2 通道注意力机制
注意力机制模块的主要功能是为了增加检测模型的数据表征能力,使网络学习到图像特征中的重要信息并抑制不重要的信息。按照注意力作用的特征形式,注意力机制可以分为基于通道的注意力和基于空间的注意力。
图像的通道信息一般代表不同的特征信息,图像的通道数越多,包含的特征信息越丰富。使用通道注意力机制来选择通道中的关键特征,同时抑制与目标无关的特征,有利于将太赫兹图像中的目标信息和背景信息分离,从而减少模型的漏检情况。图 3为通道注意力机制。
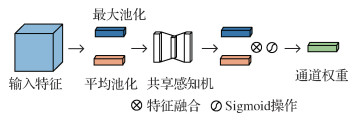
图 3中对一个输入特征分别进行空间的全局平均池化和最大池化后得到两个1维向量,然后将其输入到一个共享感知机中,再将得到的两个特征相加后经过一个Sigmoid激活函数得到权重系数Mc。最后,将得到的权重系数和原来的特征相乘即可得到经过通道注意力后的新特征。实现通道注意力的方法为
| $ \boldsymbol{M}_{c}(\boldsymbol{F})=\sigma\left(W_{1}\left(W_{0}\left(\boldsymbol{F}_{a}^{c}\right)\right)+W_{1}\left(W_{0}\left(\boldsymbol{F}_{m}^{c}\right)\right)\right) $ | (1) |
式中,Fac和Fmc分别表示原特征图经过平均池化和最大池化后的特征图,W0、W1均为感知机的可学习参数,σ表示Sigmoid函数,Mc表示得到的通道注意力权重。
2.2.3 空间注意力机制
空间注意力关注的是图像中目标的位置信息。利用空间注意力机制可以增加目标关键区域的权重,使网络关注到太赫兹图像中的重点区域,有助于网络提取到目标关键特征。图 4为空间注意力机制。
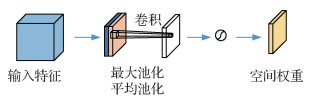
经过通道注意力后得到的特征,依次经过通道维度的平均池化和最大池化操作得到两个2维特征Fas、Fms,将其按通道维度拼接在一起后再由一个卷积层提取特征。
在CBAM的空间注意力中,Woo等人(2018)证明了使用7×7的卷积核比3×3的卷积核效果更好,因此本文同样使用7×7的卷积核来提取特征。然后,特征经过Sigmoid激活函数得到空间注意力权重Ms。为了保证最后得到的特征在空间维度上与输入的特征一致,将权重特征Ms和原始特征相乘即可得到缩放后的新特征。实现空间注意力的方法为
| $ \boldsymbol{M}_{s}(\boldsymbol{F})=\sigma\left(f\left(\left[\boldsymbol{F}_{a}^{s} ; \boldsymbol{F}_{m}^{s}\right]\right)\right) $ | (2) |
式中,Fas和Fms分别表示经过平均池化和最大池化后的特征图,f表示卷积操作,σ表示Sigmoid函数,Ms为空间注意力权重。
2.3 特征融合
神经网络通过一系列卷积和池化操作可以提取到图像中目标的相关特征。浅层网络的感知域较小,可以学习到局部区域的特征,深层网络具有较大的感知域,能够学习到更加抽象的特征。
在AFA-YOLO网络中,随着网络深度的增加,神经网络提取到特征的语义信息也就越强,这些特征对物体的大小、位置和方向等敏感性更低,因此有助于检测性能的提高。但随着网络深度的增加,特征图的分辨率会逐渐降低,并且高层特征丢失了目标外观的细节信息,因此在检测太赫兹图像中这些尺寸较小的目标时需要高分辨率的低层特征来定位目标。本文通过增加网络中的信息传输路径,如图 5中虚线所示,让低层特征和高层特征以add(特征图相加,通道数不变)方式进行特征融合,充分利用高分辨率的低层特征来提高网络模型对小尺度目标的检测效果。图 5为低层特征和高层特征的融合方式。
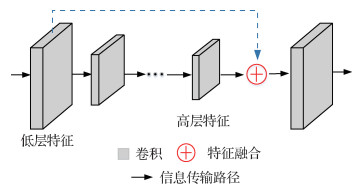
将浅层的高分辨率特征图通过下采样的方式与不同的特征进行融合,使得高层特征图能获取到细粒度的目标外观信息,从而优化对太赫兹图像中小尺度目标的定位和检测效果。add方式的特征融合方法为
| $ \begin{gathered} \boldsymbol{Z}=\sum\limits_{i=1}^{c}\left(\boldsymbol{X}_{i}+\boldsymbol{Y}_{i}\right) * \boldsymbol{K}_{i}= \\ \sum\limits_{i=1}^{c} \boldsymbol{X}_{i} * \boldsymbol{K}_{i}+\sum\limits_{i=1}^{c} \boldsymbol{Y}_{i} * \boldsymbol{K}_{i} \end{gathered} $ | (3) |
式中,X和Y分别表示两组输入特征的通道,K表示卷积核,Z表示输出特征, c为特征图通道的最大值。
3 实验结果与分析
3.1 太赫兹数据集
本文所使用的太赫兹数据集包含了7 711幅不同的太赫兹图像,每幅图像的尺寸为200×380像素, 如图 6所示。对收集到的7 711幅太赫兹图像用LabelImg软件进行标注,将图像中的检测目标分为两类,分别为phone和knife,标注过程中发现所有目标均小于32×32像素。标注完成后,每一幅太赫兹图像都对应有一个XML(extensible markup language)格式的标注文件,文件里记录着目标的位置信息。最后,将太赫兹图像制作成VOC(visual object classes)类型的数据集。

3.2 实验设置
表 1为本文实验环境配置表,实验在Ubantu16.04系统下进行,处理器型号为Intel(R) Core(TM) i5-9400F CPU @ 2.90 GHz,使用Nvidia RTX 2060显卡,内存为16 GB,开发语言为python3.6,深度学习框架采用PyTorch1.6以及OpenCV3图像处理库。
表 1
实验环境配置
Table 1
Experimental environment configuration
| 运行环境 | 详细配置 |
| 系统 | Ubuntu 16.04 |
| 处理器型号 | Intel(R)Core(TM)i5-9400F CPU@2.90 GHz |
| 显卡 | NVIDIA Geforce RTX2060 |
| 内存 | 16.0 GB |
| 开发语言 | Python3.6 |
| 深度学习框架 | Pytorch1.6 |
| 图像处理库 | OpenCV3 |
在训练阶段, batchsize批量大小为4,momentum动量为0.9,decay权值衰减为0.000 5,learning_rate学习率为0.001,迭代次数为300 epoch。
3.3 评价指标
目标检测算法的评价指标有平均精度均值、漏警率以及检测速度。平均精度均值代表所有类别检测的平均准确率,平均准确率(average precision, AP)由查准率p和召回率r计算得到。漏警率是衡量检测模型的重要指标之一,尤其是对小尺度目标的检测,判断模型是否将图像中所有目标全部检测出来。检测速度是评估一个检测器的实时性指标,通常用每秒处理帧数表示,帧率(frames per second, FPS)越大,说明检测器的实时性越好,当FPS值大于30帧/s时即可做到实时性检测。各指标公式为
| $ p=\frac{T P}{T P+F P} $ | (4) |
| $ r=\frac{T P}{T P+F N} $ | (5) |
| $ AP=\sum\limits_{k=1}^{n}\left(r_{k+1}-r_{k}\right) p_{k} $ | (6) |
| $ mAP=\frac{1}{Q} \sum\limits_{q=1}^{Q} A P(q) $ | (7) |
| $ MA=\frac{F N}{T P+F N} $ | (8) |
式中,查准率p为正确检测的正样本数占检测结果中正样本总数的比例,召回率r为正确检测的正样本数占实际正样本总数的比例,真阳性(TP)表示正确检测的正样本数、假阳性(FP)表示实际为负样本但检测为正样本的数量、假阴性(FN)表示实际为正样本但检测为负样本的数量,Q表示检测的类别数,AP(q)表示q类别的平均准确率,MA为漏警率,用来衡量模型漏检程度。
3.4 实验结果与分析
3.4.1 实验结果
为了说明本文方法AFA-YOLO相比YOLOv4的优劣之处,对比了两者的模型参数量以及模型的推理时间。从表 2可以看出,AFA-YOLO相比YOLOv4,模型的参数量大小增加了1.25 M,因此推理时间也增加了3 ms。
表 2
模型参数与推理时间
Table 2
Model parameters and inference time
| 模型 | 参数量/M | 推理时间/ms |
| YOLOv4 | 62.71 | 27 |
| AFA-YOLO(本文) | 63.96 | 31 |
| 注:加粗字体表示各列最优结果。 | ||
本文对训练过程进行了可视化,其中图 7、图 8分别对比了AFA-YOLO与YOLOv4训练时的mAP和recall的变化曲线。
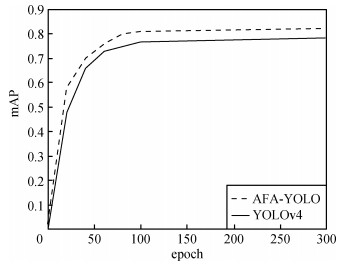
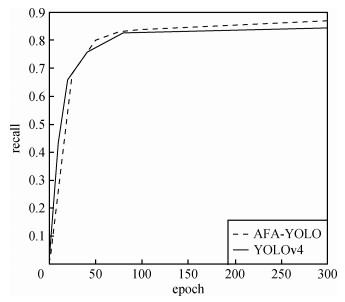
图 7中模型的mAP值随训练周期逐渐增大,在训练300 epoch后,其中AFA-YOLO的值最终稳定在82.36%,YOLOv4的值最终稳定在78.44%,AFA-YOLO比YOLOv4高了3.92%。图 8中模型的召回率同样随着训练周期的增加逐渐升高,AFA-YOLO最终稳定在87.22%,YOLOv4最终稳定在84.57%, AFA-YOLO比YOLOv4高了2.65%。
从实验结果分析得到,本文AFA-YOLO方法虽然在模型参数量上有所增加,但是能带来更高的检测精度以及更高的召回率。
3.4.2 消融实验
为了充分探究AFA-YOLO中每个模块的改进对检测模型的影响,进行消融实验,对比YOLOv4、YOLOv4+非对称特征注意力、YOLOv4+特征融合和本文AFA-YOLO算法。实验结果如表 3所示。由表 3可知, 在网络中增加了非对称特征注意力模块后,mAP提升了1.99%,MA降低了2.1%,FPS降低了2.85帧/s;在网络中增加了特征融合后,mAP提升了1.53%,MA降低了1.98%,FPS降低了1.31帧/s;在同时加入非对称特征注意力模块和特征融合后,mAP提升了3.96%,MA降低了2.65%,FPS降低了4.06帧/s。从检测角度看,在网络中添加非对称特征注意力模块和特征融合后虽然检测速度有所降低,但是能有效让检测模型学习到太赫兹图像中目标的特征,从而能有效提升检测模型的检测精度,同时降低模型的漏警率。
表 3
消融实验
Table 3
Ablation experiment
| 算法 | mAP/% | MA/% | FPS/(帧/s) |
| YOLOv4 | 78.44 | 15.43 | 36.32 |
| YOLOv4+非对称特征注意力 | 80.43 | 13.33 | 33.47 |
| YOLOv4+特征融合 | 79.97 | 13.45 | 35.01 |
| AFA-YOLO(本文) | 82.36 | 12.78 | 32.26 |
| 注:加粗字体表示各列最优结果。 | |||
图 9为AFA-YOLO模型对太赫兹图像检测的结果图,图中的数值代表了模型判断为该类别的置信度,从检测效果来看,AFA-YOLO模型能很好地将太赫兹图中的目标检测出来,并且达到了较高的精度。

3.4.3 与其他方法的对比
为了说明AFA-YOLO模型的有效性,本文对比了主流的目标检测算法在太赫兹数据集中的检测效果。其中,Faster R-CNN、Mask R-CNN为两阶段目标检测算法,SSD、YOLOv3、YOLOv4为单阶段目标检测算法。实验结果如表 4所示,与其他检测算法相比,AFA-YOLO检测算法中的非对称特征注意力模块提升了对太赫兹图像中目标的检测精度,同时能有效降低漏警率,并且特征融合也有利于对太赫兹图像中的目标检测,AFA-YOLO相比原YOLOv4算法虽然检测速度有所降低,但是仍能满足实时性的检测要求。
表 4
不同检测算法的比较
Table 4
Comparison of different detection algorithms
| 模型 | AP(phone)/% | AP(knife)/% | mAP/% | MA/% | FPS/(帧/s) |
| Faster R-CNN | 80.83 | 81.71 | 81.27 | 15.28 | 12.45 |
| Mask R-CNN | 81.06 | 81.92 | 81.49 | 14.76 | 6.40 |
| SSD | 76.87 | 81.55 | 79.21 | 15.89 | 34.01 |
| YOLOv3 | 75.09 | 80.27 | 77.68 | 16.13 | 38.42 |
| YOLOv4 | 77.03 | 79.84 | 78.44 | 15.43 | 36.32 |
| AFA-YOLO(本文) | 81.15 | 83.56 | 82.36 | 12.78 | 32.26 |
| 注:加粗字体表示各列最优结果。 | |||||
4 结论
随着太赫兹技术的发展,基于太赫兹成像的人体安检技术成为安检领域中的研究热点。但太赫兹图像中目标较小、特征有限,并且背景信息易对目标信息产生干扰,这成为太赫兹图像检测的难点问题。本文以YOLOv4算法为基础,提出了一种融合非对称特征注意力的目标检测网络AFA-YOLO。首先,AFA-YOLO网络在浅层网络中使用非对称卷积来增强网络的特征提取能力,能在目标特征有限的太赫兹图像中提取到有效的目标特征;其次,网络中加入了CBAM注意力机制,通过通道注意力和空间注意力使网络模型学习到图像中目标的重要特征,解决背景信息和目标信息干扰的问题,同时让检测模型关注图像中的重点区域;最后通过增加网络中低层到高层的信息传输路径对高层特征增强,将低层高分辨率特征和高层具有丰富语义信息的特征进行融合,充分利用低层特征检测太赫兹图像中的小尺度目标。实验结果表明,本文提出的AFA-YOLO方法在太赫兹数据集上的检测精度提升了3.96%,达到了82.36%;漏警率降低了2.65%,为12.78%;FPS降低了4.06帧/s,为32.26帧/s,达到了较好的检测效果。本文与其他检测算法进行了对比,AFA-YOLO算法在检测精度和漏警率的表现上优于其他检测算法,但由于在网络模型中增加了非对称卷积,导致模型的参数量增多,因此AFA-YOLO在检测速度上慢于YOLOv3、YOLOv4以及SSD算法,但是仍然能满足实时性的检测要求。
由于本文中只有knife和phone两类检测对象,图像样本上缺乏多样性,因此在以后的研究工作中, 将陆续增加检测对象,将安检中的违禁品纳入其中,并扩充太赫兹图像数据集以提高本模型的实用性和鲁棒性。
参考文献
-
Bochkovskiy A, Wang C Y and Liao H Y M. 2020. YOLOv4: optimal speed and accuracy of object detection [EB/OL]. [2021-03-01]. https://arxiv.org/pdf/2004.10934.pdf
-
Chen B Q, Deng T. 2019. The vehicle object detection research based on improved SSD algorithm. Journal of Chongqing University of Technology (Natural Science), 33(1): 58-63, 129 (陈冰曲, 邓涛. 2019. 基于改进型SSD算法的目标车辆检测研究. 重庆理工大学学报(自然科学), 33(1): 58-63, 129) [DOI:10.3969/j.issn.1674-8425(z).2019.01.009]
-
Ding X H, Guo Y, Ding G G and Han J G. 2019. ACNet: strengthening the kernel skeletons for powerful CNN via asymmetric convolution blocks//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Seoul, Korea (South): IEEE: 1911-1920 [DOI: 10.1109/ICCV.2019.00200]
-
Feng H, An D Y, Tu H, Bu W H, Wang W J, Zhang Y H, Zhang H K, Meng X X, Wei W, Gao B X, Wu S. 2020. A passive video-rate terahertz human body imager with real-time calibration for security applications. Applied Physics B, 126(8): #143 [DOI:10.1007/s00340-020-07496-3]
-
Gao M F, Yu R C, Li A, Morariu V I and Davis L S. 2018. Dynamic zoom-in network for fast object detection in large images//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE: 6926-6935 [DOI: 10.1109/CVPR.2018.00724]
-
Guo F, Zhang Y X, Tang J, Li W Q. 2021. YOLOv3-A: a traffic sign detection network based on attention mechanism. Journal on Communications, 42(1): 87-99 (郭璠, 张泳祥, 唐琎, 李伟清. 2021. YOLOv3-A: 基于注意力机制的交通标志检测网络. 通信学报, 42(1): 87-99) [DOI:10.11959/j.issn.1000-436x.2021031]
-
He K M, Gkioxari G, Dollár P and Girshick R. 2017. Mask R-CNN//Proceedings of 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE: 2980-2988 [DOI: 10.1109/ICCV.2017.322]
-
Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu C Y and Berg A C. 2016. SSD: single shot MultiBox detector//Proceedings of the 14th European Conference on Computer Vision. Amsterdam, the Netherlands: Springer: 21-37 [DOI: 10.1007/978-3-319-46448-0_2]
-
Liu Z G, Li D Y, Ge S S, Tian F. 2020. Small traffic sign detection from large image. Applied Intelligence, 50(1): 1-13 [DOI:10.1007/s10489-019-01511-7]
-
Mittleman D M. 2017. Perspective: terahertz science and technology. Journal of Applied Physics, 122(23): #230901 [DOI:10.1063/1.5007683]
-
Redmon J, Divvala S, Girshick R and Farhadi A. 2016. You only look once: unified, real-time object detection//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Vegas, USA: IEEE: 779-788 [DOI: 10.1109/CVPR.2016.91]
-
Redmon J and Farhadi A. 2017. YOLO9000: better, faster, stronger//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE: 6517-6525 [DOI: 10.1109/CVPR.2017.690]
-
Redmon J and Farhadi A. 2018. YOLOv3: an incremental improvement[EB/OL]. [2021-03-01]. https://arxiv.org/pdf/1804.02767.pdf
-
Ren S Q, He K M, Girshick R, Sun J. 2017. Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(6): 1137-1149 [DOI:10.1109/TPAMI.2016.2577031]
-
Sommer L W, Schuchert T and Beyerer J. 2017. Fast deep vehicle detection in aerial images//Proceedings of 2017 IEEE Winter Conference on Applications of Computer Vision (WACV). Santa Rosa, USA: IEEE: 311-319 [DOI: 10.1109/WACV.2017.41]
-
Wang K X, Liew J H, Zou Y T, Zhou D Q and Feng J S. 2019. PANet: few-shot image semantic segmentation with prototype alignment//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Seoul, Korea (South): IEEE: 9196-9205 [DOI: 10.1109/ICCV.2019.00929]
-
Woo S, Park J, Lee J Y and Kweon I S. 2018. CBAM: convolutional block attention module//Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer: 3-19 [DOI: 10.1007/978-3-030-01234-2_1]
-
Xiao H, Zhang R Y, Wang H, Zhu F, Zhang C, Dai H N and Zhou Y B. 2018. R-PCNN method to rapidly detect objects on THz images in human body security checks//2018 IEEE SmartWorld, Ubiquitous Intelligence and Computing, Advanced and Trusted Computing, Scalable Computing and Communications, Cloud and Big Data Computing, Internet of People and Smart City Innovation. Guangzhou, China: IEEE: 1777-1782 [DOI: 10.1109/SmartWorld.2018.00300]
-
Yang X, Wu T, Zhang L, Yang D, Wang N N, Song B, Gao X B. 2019. CNN with spatio-temporal information for fast suspicious object detection and recognition in THz security images. Signal Processing, 160: 202-214 [DOI:10.1016/j.sigpro.2019.02.029]
-
Zhang J S, Xing W J, Xing M D, Sun G C. 2018. Terahertz image detection with the improved faster region-based convolutional neural network. Sensors, 18(7): #2327 [DOI:10.3390/s18072327]


